Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
一、基本概念
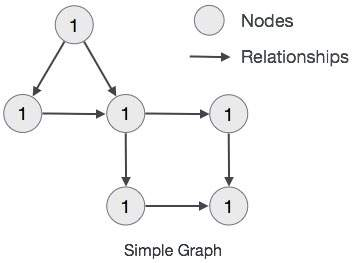
1. 标签(Label)
在Neo4j中,一个节点可以有一个以上的标签,从现实世界的角度去看,一个标签可以认为节点的某个类别,比如BOOK、MOVIE等等。
2. 节点(Node)
节点是指一个实实在在的对象,这个对象可以有好多的标签,表示对象的种类,也可以有好多的属性,描述其特征,节点与节点之间还可以形成多个有方向(或者没有方向)的关系。
3. 关系(Relationship)
用来描述节点与节点之间的关系,这也是图数据与与普通数据库最大的区别,正是因为有这些关系的存在,才可以描述那些我们普通行列数据库所很难表示的网状关系,比如我们复杂的人际关系网,所谓的六度理论,就可以很方便的用图数据库进行模拟,比如我们大脑神经元之间的连接方式,都是一张复杂的网。
有一点需要重点注意,关系可以拥有属性。
4. 属性(Property)
描述节点的特性,采用的是Key-Value结构,可以随意设定来描述节点的特征。
二、查询语法(CQL)
| 序号 | 关键字 | 关键字作用 |
|---|---|---|
| 1 | CREATE | 创建 |
| 2 | MATCH | 匹配 |
| 3 | RETURN | 加载 |
| 4 | WHERE | 过滤检索条件 |
| 5 | DELETE | 删除节点和关系 |
| 6 | REMOVE | 删除节点和关系的属性 |
| 7 | ORDER BY | 排序 |
| 8 | SET | 添加或更新属性 |
1. 基本查找match return
neo4j使用的查询语法是Cypher语法与我们常用的SQL查询语法不一样,但是在初步的学习之后,觉得他们之间使用的思路有很多重叠的地方,整个语句的执行流程也和SQL有比较多相似的地方。
1 | # 创建两个节点,一个子节点(Mask),一个父节点(Old_mask),他们之间是属于父子关系 |
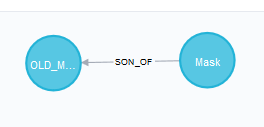
返回数据:

2. 查找指定节点、指定属性、指定关系的节点、关系
1 | # MATCH 匹配命令 |
命令执行结果:

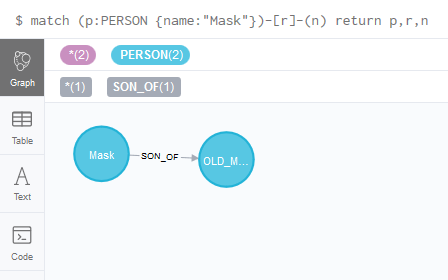
where关键字类似于SQL里面的where关键字,可以通过运算符== >= ...来过滤一些查询条件。
3. 对查找结果进行排序order by,并限制返回条数 limit
order by关键字与SQL里面是一样的操作,后面跟上需要根据排序的关键字,limit的操作是指定输出前几条
1 | # 这里利用order by来指定返回按照Person.name来排序 |
查找结果:

4. 删除节点delete命令
删除节点的操作也是通过dlete来操作,如果被删除的节点存在Relationship,那么单独删除该节点的操作会不成功,所以如果想删除一个已经存在关系的节点,需要同时将关系进行删除。
删除一个不存在Relationship节点,会报错:
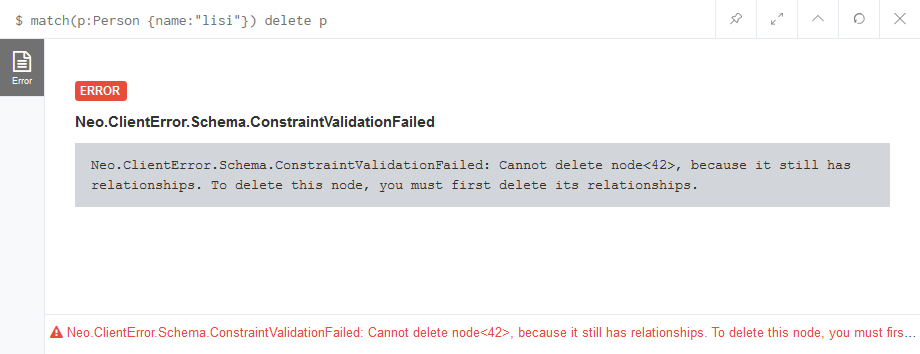
删除一个节点记忆与他有关的关系,成功:
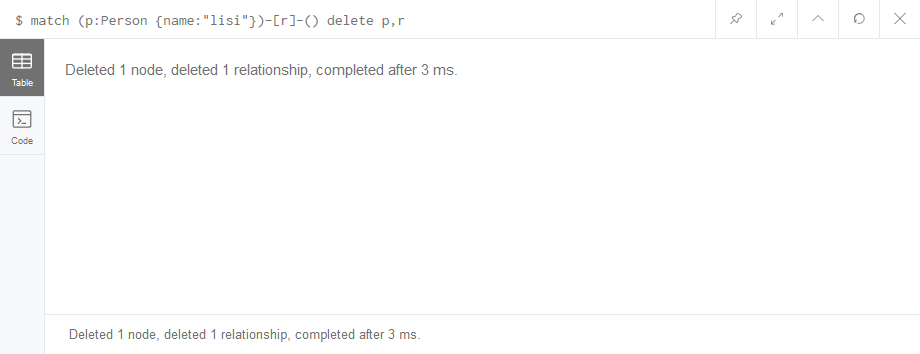
1 | # 删除指定条件的节点 |
5. 删除属性remove命令
remove命令是用来删除节点或者关系的属性
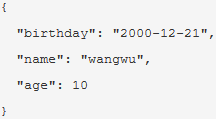
删除属性前的节点:
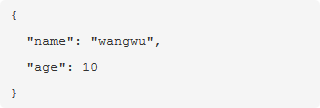
删除birthday属性后的节点:
6. neo4j的字符串函数
upper,lower,substring,replac四种字符串的操作,其中upper与lower在将来的版本中会被修改为toupper/tolower
大写转换操作结果:

7. 聚合函数AGGREGATION
常用的聚合函数有COUNT、MAX、MIN、AVG、SUM等五种。
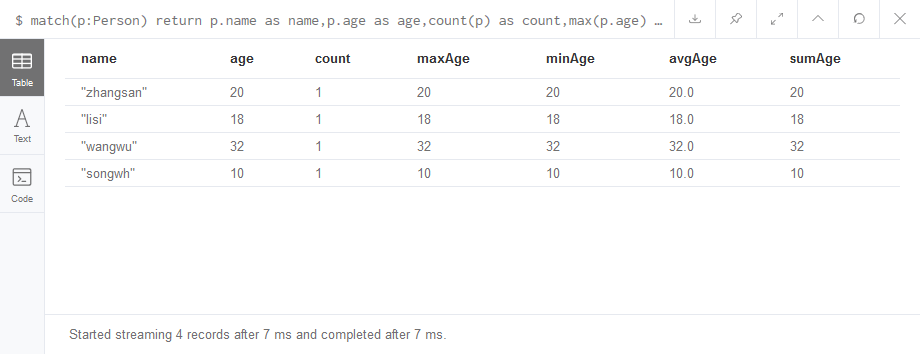
1 | match(p:Person) return p.name as name,p.age as age,count(p) as count,max(p.age) as maxAge,min(p.age) as minAge,avg(p.age) as avgAge,sum(p.age) as sumAge |
聚合函数操作结果:
8. 关系函数
| 序号 | 函数名 | 函数功能描述 |
|---|---|---|
| 1 | STARTNODE | 查找关系的起始点 |
| 2 | ENDNODE | 查找关系的终点 |
| 3 | ID | 查找关系的ID |
| 4 | TYPE | 查找关系的类型,也就是我们在图表中看到的名称 |
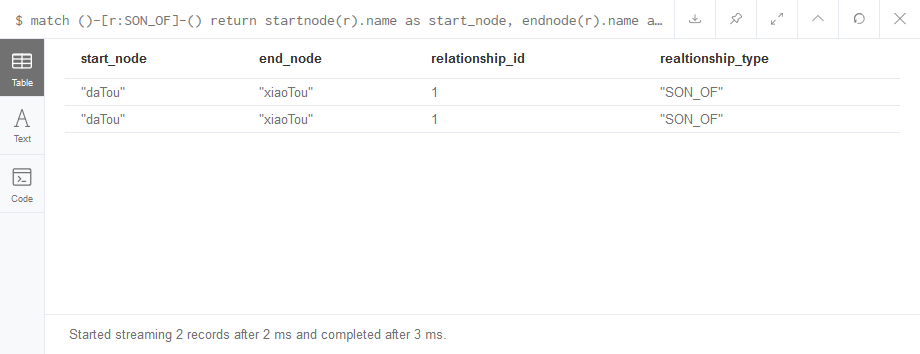
1 | # 先获取关系,然后通过关系函数来获取关系的id、type、起始节点、终止节点等等信息 |
关系查询结果:
在Java中使用
1. 原生的Neo4j Java API
Neo4j Java API的设计思路及基本概念:
- Label接口,表示标签,实现这个接口的类,就可以当标签使用;
- Relationship接口,别是关系,实现这个接口的类,就可以表示关系;
- 通过
GraphDatabaseFactory这个类的实例化对象可以获取GraphDatabaseService实例; GraphDatabaseService实例对象,可以获取一个操作事务,通过这个事务可以实现任何操作异常的回滚,操作成功需要调用tx.success()方法;GraphDatabaseService对象可以创建节点node;- 节点
node可以设置属性setProperty(key,value); - 节点
node可以创建关系Relationship,Relationship也可以通过setProperty(key,value)来设置属性;
枚举标签Label
1 | package com.tp.ne4oj.java.examples; |
枚举关系Realationship
1 | package com.tp.neo4j.java.examples; |
获取操作对象
1 | GraphDatabaseFactory dbFactory = new GraphDatabaseFactory(); |
启动neo4j数据库事务
1 | try (Transaction tx = graphDb.beginTx()) { |
整体代码
1 | package com.tp.neo4j.java.examples; |
Cypher执行引擎,让Java执行原生CQL语句
1 | package com.tp.neo4j.java.cql.examples; |
Spring Data neo4j 的操作
操作思路:
- 创建一个与图数据库存储数据对应的实体类
entity,并进行必要的注解; dao层接口继承Spring data Neo4j类GraphRepository、GraphTemplate、CrudRepository、PaginationAndSortingRepository,这个和springDataJPA也比较类似;
基本导包操作,pom.xml
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
最后
neo4j与java的结合有很多的方式,据目前我所知道的就有原生api、driver方式、springData neo4j等三种方式。